1. Vaex란 무엇인가?
Vaex는 대용량 데이터를 효율적으로 처리하기 위해 탄생한 Python 라이브러리로, 가장 널리 쓰이는 데이터 프로세싱 도구인 Pandas의 한계를 뛰어넘는 성능을 제공합니다. 공식 문서를 보면, 아래와 같이 “Vaex란 무엇인가?”를 4문장으로 요약하고 있는데요. 여기서 첫 문장과 마지막 문장만 인용해 보겠습니다.
” Vaex is a python library for lazy Out-of-Core DataFrames (similar to Pandas), to visualize and explore big tabular datasets. … Vaex uses memory mapping, a zero memory copy policy, and lazy computations for best performance (no memory wasted). “
이 두 문장에서 가장 주목해야 할 키워드는 Out-of-Core 그리고 lazy computation입니다.
Out-of-Core란?
” In computing, external memory algorithms or out-of-core algorithms are algorithms that are designed to process data that are too large to fit into a computer’s main memory at once. “
Out-of-Core란 RAM에 모두 올리기에는 너무 큰 데이터셋을, 디스크에서 필요한 부분만 조각조각 가져와 처리하는 방식을 말합니다.
Lazy Computation이란?
다음으로 Lazy Computation 방식은, 연산을 수행할 때 데이터를 즉시 처리하는 것이 아니라, “실행 계획”만 세우고 실제 결과가 필요할 때 실행하는 것을 의미합니다.
이제 Vaex의 비결이 무엇인지 감이 좀 오시지 않나요? 바로 이 두 데이터 처리 방식이 Vaex를 Pandas 보다 더 빠르게, 제한된 RAM 용량보다 훨씬 큰 데이터셋을 다룰 수 있도록 만들었습니다.
반면, Pandas는 이러한 방식으로 동작하지 않습니다. Pandas는 데이터를 처리할 때 모든 데이터를 메모리에 로드한 후, 즉시 연산하는 방식(Eager Execution)을 사용합니다. 따라서 데이터가 메모리보다 크면 Out of Memory(OOM) 오류가 발생할 가능성이 높고, 중간 계산 결과가 많아질수록 성능이 급격히 저하될 수 있습니다. 또한, 큰 데이터를 메모리에 모두 올리는 것 자체만으로 많은 시간을 소모하기도 하죠.
2. Pandas와 Vaex, Performance 비교
이번에는 실제 데이터셋을 이용하여 Pandas와 Vaex의 성능을 비교해 보겠습니다. 제가 사용한 데이터셋은 NYC의 Taxi & Limousine Commission (TLC) Trip Record Data입니다. (https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page) 이 데이터셋은 뉴욕시에서 운행된 택시 및 리무진의 운행 기록을 포함하고 있으며, 각 운행에 대한 승차 및 하차 시각, 거리, 승차 장소, 하차 장소 등 다양한 정보를 담고 있습니다.
저는 2024년 3월의 운행 기록이 담긴 데이터셋을 parquet 파일로 다운로드 받았습니다. 약 500MB 크기의 데이터였는데요. Vaex에서 가장 권장하는 파일 형태인 hdf5 파일로 데이터셋을 변환하게 되면, 약 3GB 까지 크기가 증가했습니다.
‘효율적으로 데이터를 처리할 수 있는 파일 포맷으로‘ 데이터를 처리한다는 가정 하에 비교를 진행하고자, Pandas와 Vaex를 각각 parquet과 hdf5 파일을 이용하여 데이터 처리를 진행해 보겠습니다.
먼저, Pandas 코드입니다.
import pandas
# NOTE: PART_01, LINE 4 (5.5s)
df = pandas.read_parquet("/Users/dohyeonan/data/fhvhv_tripdata_2024-03.parquet")
# NOTE: PART_02, LINE 7 (6s)
filtered_df = df[df.hvfhs_license_num == "HV0003"] # 고객 호출 기반 차량 서비스를 "Uber"로 한정
# NOTE: PART_03, LINE 8-13 (20.5s)
# NOTE: 참고로 PU는 pickup, DO는 dropoff를 뜻함.
groupby_df = filtered_df.groupby('PULocationID').agg(
cnt=('PULocationID', 'count'),
avg_trip_time=('trip_time', 'mean'),
drop_off_locations=('DOLocationID', lambda x: list(x)),
drop_off_location_count=('DOLocationID', 'nunique'),
).reset_index().sort_values(by='drop_off_location_count', ascending=False)보시는 것처럼, 출발지 위치(PULocationID)를 기준으로 집계를 진행하고 있는데요. 해당 위치에서 출발한 기록이 얼마나 있는지, 운행 시간 평균, 목적지 ID 목록, 그리고 목적지 총개수를 계산하는 집계 연산을 진행하고 있습니다.
결과는 다음과 같습니다.
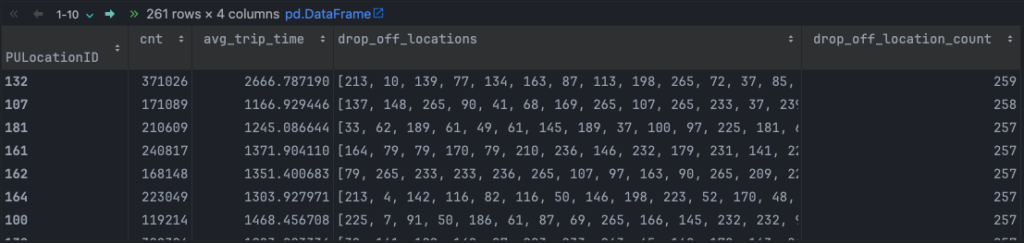
위 결과를 얻는 과정에서 유의미한 메모리 사용량 변화는 거의 없었지만, (오히려 메모리는 1GB 정도 감소했습니다.🤔) 사용량이 없던 swap 메모리는 5GB까지 올라갔습니다. (macOS M1, 8GB RAM 환경에서 테스트)
작업 시간의 경우,
PART_01(LINE 4)을 수행하는 데 5.5초 🏃♂️
PART_02(LINE 7)을 수행하는 데 6초 🏃♂️
PART_03(LINE 11-16)을 수행하는 데 20.5초 🏃♂️
소요됐습니다.
이번엔 Vaex에서의 코드를 확인해 볼까요? 완전히 똑같은 작업을 수행하는 코드입니다.
import vaex
# NOTE: PART_01, LINE 4 (1.4s)
df = vaex.open('/Users/dohyeonan/data/fhvhv_tripdata_2024-03.hdf5')
# NOTE: PART_02, LINE 7, lazy computation 방식으로 인해 계산을 미루는 부분. (0.01s)
filtered_df = df[df.hvfhs_license_num == "HV0003"] # 고객 호출 기반 차량 서비스를 "Uber"로 한정
# NOTE: PART_03, LINE 8-16
# NOTE: 참고로 PU는 pickup, DO는 dropoff를 뜻함. (0.9s)
groupby_df = filtered_df.groupby(by='PULocationID').agg(
{
'cnt': vaex.agg.count('PULocationID'),
'avg_trip_time': vaex.agg.mean('trip_time'),
'drop_off_locations': vaex.agg.list('DOLocationID'),
'drop_off_location_count': vaex.agg.nunique('DOLocationID')
}
).sort(['drop_off_location_count'])이전과 같은 결과의 groupby dataframe을 얻는 과정에서, 유의미한 메모리 사용량 변화는 없었습니다. Pandas 코드에서는 아주 높게 올라갔던 swap 메모리 사용량도 Vaex 코드에서는 변화가 없었습니다. (테스트 환경은 위와 동일)
놀랍게도 작업 시간의 경우는
PART_01(LINE 4)을 수행하는 데 1.4초 ⚡️
PART_02(LINE 7)을 수행하는 데 0.01초 ⚡️
PART_03(LINE 11-16)을 수행하는 데 0.9초 ⚡️
소요됐습니다.
Pandas 코드로 얻은 결과와 비교해 보면, 최소 10배 이상의 성능 향상을 확인할 수 있었습니다. 특히, 메모리 사용량이 압도적으로 적었는데요. 흔히 “Vaex의 멀티스레딩 활용 때문 아닌가요?“라고 생각할 수도 있지만, 이번 테스트에서는 멀티스레딩 여부를 제외하고도 성능 차이가 컸습니다. Vaex의 핵심 강점은 Out-of-Core 방식을 활용해 불필요한 메모리 낭비를 최소화하고, lazy computation을 통해 필요한 시점에만 연산을 진행하는 데 있습니다. 단순히 병렬 처리를 활용한 속도 향상이 아니라, 데이터 처리 방식 자체에서 오는 효율성이 주요한 차이를 만들었다는 점을 확인할 수 있었습니다.
3. 다음 글에서는…
- “실무에서 직접 터득한 Vaex 사용 노하우 (2편: 실제 서비스에서 데이터 처리속도 3배 높인 비결)“
- “실무에서 직접 터득한 Vaex 사용 노하우 (3편: 이제는 Vaex의 한계를 뛰어넘어야 할 때)“
위 두 글을 이어서 연재하려고 합니다. 남은 글도 많은 관심 부탁드립니다 ☺️